Elhai J (2018). Superabundant HIP1 and other oligomers in cyanobacterial genomes: A mechanism for their gain and loss. 16th International Symposium on Phototrophic Prokaryotes, Aug 2018. pp.56-57.
Apart from strains in Group 7, there are rare cyanobacteria that do not have highly abundant HIP1 sequences. Many of these have a different highly abundant sequence (e.g. strains b, d, and k in Figure 1). Some don't have any highly abundant sequence. Those in the latter class are all strains in obligate symbiotic relationships.
The genomes without HIP1 but with a different repeated oligomer are highly informative. All genomes that have a highly repeated oligomer possess at least one modifying enzyme that methylates a cytosine residue within the oligomer, either GCGATCGC (HIP1) or one of the alternate HIPs: GGCGCC, rCCGGy, GC[G/C]GC. The correlation is so striking, it must be telling something important.
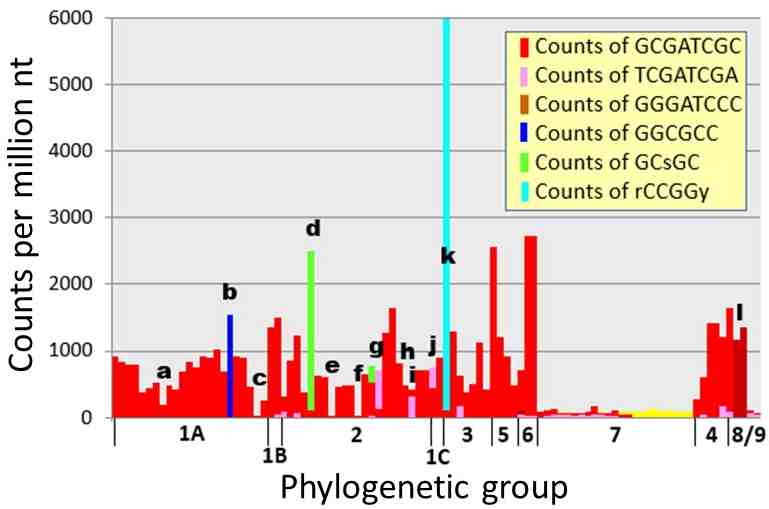
Figure 1. Counts of HIP1 and other oligomers in genomes of cyanobacteria. The counts for HIP1 are shown in red, as well as the counts for the most numerous oligomer, if not HIP1. The letters and phylogenetic groups are explained in a tree given in Elhai (2015) and Elhai (2018).
Figure 2 shows how this system could lead to high frequency sites. In the left panel, TCGATCGT is shown methylated, because most cyanobacteria possess a CGATCG-specific methylase, but the methylated C does not participate in methyl-directed mismatch repair, because it is not part of a G[Me]C pair. If the 5' T is mutated to a G, then a G[Me]C pair appears to direct the degradation of the opposite strand. This makes the mutation to G permanent. Only mutations to G in this position create the conditions to do this. In the same way, G[Me]C-dependent mismatch repair bias mutation towards the creation of the other methylase recognition sites.
There is no biochemical evidence for or against the existence of G[Me]C-dependent mismatch repair in cyanobacteria. Its existence would therefore constitute strong support of the model.
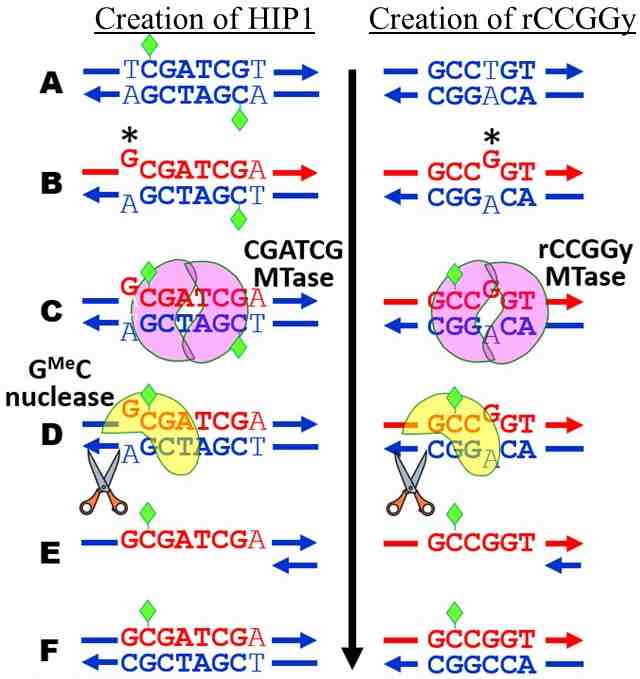
Figure 2. Model to explain the high abundance of HIP sites. Blue DNA = old strand; red DNA = newly synthesized strand; Green diamonds = methylation; * = mutation. The left panel shows the first step in creating GCGATCGC (HIP1) from a CGATCG site. The right panel shows the creation of a rCCGGy site.